가설의 검증은 모집단의 모수의 값에 대한 가설(Hypothesis)를 먼저 설정하고, 그 가설의 성립여부를 표본집합의 데이터를 분석하여 통계적인 방법으로 확인하는 과정이다. 이는 통계적 추정(Statistical Estimation)이 표본집합의 데이터로 모수를 추정하는 것과는 반대의 개념이라 할 수 있다.
귀무가설 (Null Hypothesis) 와 대립가설 (Alternative Hypothesis)
귀무가설은 검증의 대상이 되는 가설이다. 대립가설은 검증의 대상이 되는 가설에 대립되는 (부정하는 ) 가설이다. 귀무가설은 H0로 하고, 대립가설을 H1으로 하자. 통계적 검정 과정에 의해, 어떠한 가설에 대해 채택(accept)를 하거나 기각(reject)을 할 수 있을 것이다. 여기서 채택을 하지 않았다고 해서 기각이라는 의미는 아니며, 기각을 하지 않았다고 해서 채택이라는 의미는 아니라는 점을 유의해야 한다.
귀무가설 H0 또는 대립가설 H1에 대해 채택 또는 기각을 하는 경우에, 다음과 같은 경우의 수가 있을 수 있다.

상기 표에서, 잘못된 결정을 내리는 경우는 다음 두 가지이다.
- 제1종의 과오 (Type I error): 귀무가설 H0가 사실임에도 그것을 기각하는 경우. 이 확률을 α로 정의한다. 이 확률 α를 유의수준 또는 위험률 (level of significance)라고 한다.
- 제2종의 과오(Type II error): 대립가설 H1이 거짓임에도 그것을 채택하는 경우. 이 확률을 β로 정의하면, 귀무가설의 거짓을 찾아낼 확률은 (1 – β) 가 되며, 검정력 (power of test) 이라고 하다.
통계적 가설검정의 목적은 제1종의 과오를 가능한 한 줄이고, 귀무가설의 거짓을 찾아내는 검정력을 크게 하는 것이다. 다음과 같은 관련된 용어에 대해 정리한다.
- 검정 통계량 (Test Statistics): 귀무가설이 정해지면, 모수에서 표본을 추출하고, 주어진 가설을 기각 또는 채택하기 위한 통계량을 정해야 한다. 이것을 검정 통계량이라고 한다.
- 기각역(Reject Region) / 채택역(Acceptance Region) / 기각치(Critical Value): 검정 통계량의 분포를 이용하여 그 값이 기각역에 있으면 귀무가설을 기각하고, 채택역에 있으면 채택한다. 기각치는 기각역과 채택역을 나누는 경계값을 의미한다.
- 한쪽검정(One-tailed Test) 및 양쪽검정(Two-tailed Test): 귀무가설(또는 이에 따르는 대립가설)이 단항 부등식을 가지고 있어서 채택역과 기각역이 서로 분리되는 경우가 한쪽검정(One-tailed Test)이다. 만일 등호, 부등호 등의 기호로 기각역이 채택역의 양쪽에 위치하는 경우라면 양쪽검증(Two-tailed Test)라고 한다.
이항분포를 이용한 검정이 판정 방법의 예
어떠한 공정에서 제품의 불량률을 p로 정의하고, 그 값이 맞는 지를 확인하기 위해 다음의 가설을 세웠다고 하자.
- 귀무가설, H0 : p ≤ 0.3
- 대립가설, H1 : p > 0.3
이 가설에서는, 이 공정의 불량률 p가 0.3 이하일 것 (즉, 한쪽만 검정하면 되는 One-tailed Test)으로 가정하고 있다. 이 가설이 맞는지를 어떻게 검증하는 지에 대해 알아보도록 한다.
이러한 조건의 검정 통계량은, 불량률이 p인 베르누이 시행이 n번 반복 시행되었을 때, 확률변수 X를 “n번 시행에서 불량품의 개수”로 정의한 이항분포 B(n, p)를 따른다. 이항분포의 확률밀도함수 및 기대값, 분산은 다음과 같다 (이전 포스팅 참고).
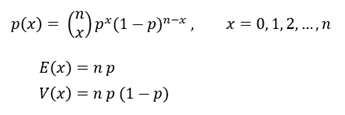
포본으로, 공정 생산품 중에서(모수에서) 랜덤하게 20개 (n=20)를 추출하기로 한다. 확률변수 X는 20개 중에서 발견된 불량품의 수로 정의한 바 있다. 샘플의 크기가 20이므로, 확률변수 X는 0, 1, 2, …. , 20 중 어느 한 값을 가질 것이다.
그렇다면, 주어진 가설을 어떻게 검정할 것인가? 검정통계량(test statistics), X의 값으로부터 다음의 예를 생각해 볼 수 있다.
- X ≥ 8 이면, 귀무가설 H0를 기각한다. 이 수식이 기각역에 대한 정의로 볼 수 있다.
- X < 8 이면, 귀무가설 H0를 채택한다. 이 수식을 채택역에 대한 정의로 볼 수 있다.
제1종의 과오를 범할 확률을 α, 제2종의 과오를 범할 확률을 β라고 하였다. 이것을 검증하고자 하는 확률 p와 검정력함수 r = r(p) 를 도입하여 다음과 같이 나타내도록 한다.
- α(p) = r(p), p ≤ 0.3
- β(p) = 1 – r(p), p > 0.3
주어진 p에 따라 검정력함수 r(p) 가 어떻게 되는 지는 주어진 조건에서의 확률분포곡선을 따른다. 앞서 본 바와 같이, 이 경우는 이산확률분포 -> 이항분포 (Binomial Distribution)가 가장 적합하다. 검정력 함수를 다음과 같이 정의하고, 미니탭을 이용하여 이항분포조건에서 검정력곡선을 구해보도록 하자.
- r(p) = P[ X≥8 | p ]
이를 위해, 먼저 이항분포(Binomial Distribution)의 누적확률분포곡선(Cumulative Probability)을 각각 다른 p를 가진 조건에서 구해본다.
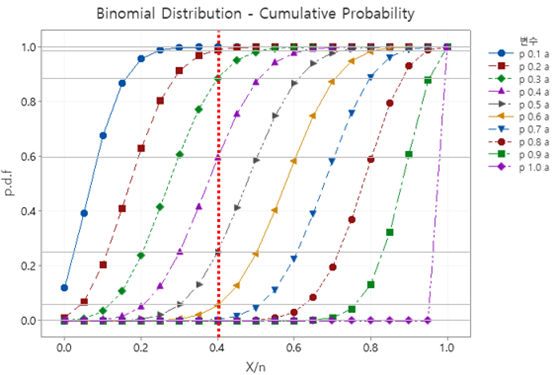
위 그림에서, 수평축은 X/n 으로 정의하였다. 샘플의 크기 n = 20 이고, X는 주어진 샘플의 크기 n에서 발견된 불량품의 개수이다. X = 8 이 귀무가설 정의에서 기각치(Critical value)에 해당한다. X/n = 8/20 = 0.4 를 세로 점선으로 표기하고, 각각의 p 값과 교차하는 값을 찾을 수 있다. 예를 들어 p = 0.3 (녹색) 일 때, X/n = 0.4 인 빨간 점선과 교차하는 값인 0.88667은 불량품의 개수가 0개 (X=0, X/n=0)에서 불량품의 개수가 8개(X=8, X/n=0.4) 가 되는 경우의 수에 대한 누적확률 값이 된다.
제 1종의 과오를 범할 확률, α(p)는 귀무가설 H0가 사실일 때, 이것을 기각하는 확률이므로, 기각치 X=8에 대하여 이 누적확률 범위 밖에 있을 확률이다. 따라서, 상기 곡선에서 1 – p.d.f(p, X/n) 이 된다. p의 값을 증가시키면서 (p = 0.1. 0.2, … , 1.0), r(p) = 1 – p.d.f (p, X/n = 0.4) 인 경우로 그래프를 그려보면 다음과 같다. 이것이 기각치 X = 8 (= X/n = 8/20 = 0.4) 를 가진 검정력함수 r(p) 이다.
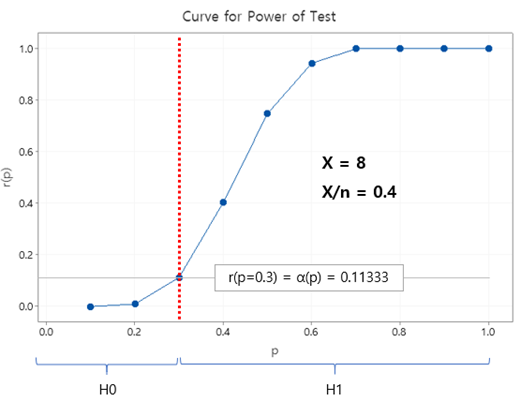
이 그래프의 왼쪽 부분 (p ≤ 0.3)은 H0가 참일 때, 오른 쪽 부분은 H1이 참일 때에 해당한다. 따라서 왼쪽 부분에서의 r(p)는 제1종의 오류를 범할 확률 α(p) = r(p)를, 오른쪽은 제2종의 오류를 범할 확률 β = 1 – r(p) 를 나타낸다.
이 곡선을 검토해 보면, 다음과 같은 사실을 알 수 있다.
- 제1종의 오류를 범할 확률 α(p)는 H0와 H1의 경계치인 p = 0.3에서 최대가 된다.
- 제1종의 오류인 α(p)를 작게 하면, 제2종의 오류인 β(p)가 커진다. 즉, 제1종의 오류와 제2종의 오류를 모두 최소로 하는 이상적인 검정방법은 표본의 크기n이 제한되어 있는 조건에서는 존재하지 않는다.
제1종의 오류와 제2종의 오류를 동시에 줄일 수 있는 방법은 표본의 크기를 증가시키는 것이다. 일반적으로 제1종의 오류 (귀무가설 H0가 사실인데, 이를 기각하는 경우)가 제2종의 오류보다 더 심각하다고 생각한다. 따라서 α에 대한 최대허용한계 (즉, 이 귀무가설 H0에 대한 검증방법 X/n – 0.4에 대한 유의수준. Level of Significance)를 정해두고, β를 최소로 하는 검정방법을 찾아보는 것이 전통적인 통계적 가설검정방법이다.
상기는 이산데이터의 확률분포에서, n번의 베르누이시행을 할 때의 검정방법에 대한 것이다. 연속확률분포 문제에서 정규분포 또는 t 분포를 할 때에도 동일한 접근방법을 취할 수 있다. 이 경우, 검정통계량은 Z = (X – μ) / σ 라는 Z 변수변환식을 이용하게 된다. 이와 관련된 주제는 다음과 같은 것이 있다. 또한 미니탭에서 어떠한 기초통계항목이 이문제를 해결하는 데 사용되는 지 연관시켜 두었다.
-
하나의 모집단에 대한 모평균 μ에 대하여, 이것이 어떤 특정의 값 μ0인지 아닌지 검정하고자 함
- 모집단이 정규분포를 하고, 표준편차 σ를 아는 경우: 미니탭/통계분석/기초통계/1-표본 Z검정
- 모집단의 표준편차 σ가 알려지지 않은 경우: 미니탭/통계분석/기초통계/1-표본t검정
-
두 개의 모집단이 있는 경우, 그 각각의 모평균 μ1과 μ2있다고 하면, 귀무가설 H0를 μ1 = μ2 (즉, 두 모집단의 평균이 서로 같은지를 검정) 조건을 주어진 유의수준 α로 검정하고자 함
- 표본의 크기가 작은 경우: 미니탭/통계분석/기초통계/2-표본t검정
- 두 개의 대응되는 데이터가 있는 경우: 미니탭/통계분석/기초통계/쌍체t검정
- 기타, 모분산의 추정과 검정, 모분산의 비율의 추정과 검정, 모비율의 추정과 검정, 모비율 차의 추정, 모결점수의 검정과 추정, 적합도/독립성/동일성의 검정 주제 등이 있다.
좀 더 자세한 부분은 다음 기회에 다루어 보도록 한다.